🔍 Neural RAG Process
DuckDB embeddings + semantic search pour retrieval augmenté
Pipeline Neural RAG
┌──────────────────────────────────────┐
│ 📄 COSMIC Documents (6 files) │
│ 170+ pages, mixed formats │
└──────────────┬───────────────────────┘
│
▼
┌──────────────────────┐
│ ✂️ Text Chunking │
│ • 512 tokens/chunk │
│ • Overlap: 50 tok │
│ • 115+ chunks total │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ 🧠 nomic-embed-text │
│ • Ollama local │
│ • 768-dim vectors │
│ • Batch: 32 chunks │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ 💾 DuckDB Storage │
│ • Vector index │
│ • 2.8 MB size │
│ • In-memory │
└──────────┬───────────┘
│
┌──────────▼───────────┐
│ 🔍 Query Processing │◄─── User Query
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ 📐 Cosine Similarity│
│ • Top-K: 5 chunks │
│ • Threshold: 0.7 │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ 📦 Context Assembly │
│ • Merge chunks │
│ • Add metadata │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ 🤖 LLM Augmentation │──► Answer
└──────────────────────┘4 Étapes du Process
1
Document Ingestion
Chargement des 6 documents COSMIC (170+ pages)
- Markdown parsing
- PDF extraction
- Text chunking (512 tokens)
- Metadata preservation
2
Embedding Generation
Transformation en vecteurs avec nomic-embed-text
- 768-dimensional vectors
- Batch processing (32 chunks/batch)
- Local Ollama inference
- ~78ms avg latency
3
DuckDB Storage
Indexation dans DuckDB vector database
- 115+ chunks indexed
- 2.8 MB database size
- In-memory for speed
- Disk persistence
4
Semantic Search
Recherche par similarité cosinus
- Query embedding
- Cosine similarity calculation
- Top-K retrieval (k=5)
- Context assembly
Spécifications Techniques
Documents
6 files
170+ pages
Chunks
115+
512 tokens each
Vector Dimension
768
nomic-embed-text
Database Size
2.8 MB
DuckDB
Avg Latency
78ms
embedding generation
Top-K Retrieval
5
most relevant chunks
💡 Avantages Clés
- 100% Local: Ollama inference = zero cloud dependency
- Fast Search: 78ms average latency for semantic retrieval
- Compact: 2.8 MB total footprint for 170+ pages
- Precision: Cosine similarity threshold 0.7 filters noise
- Scalable: DuckDB handles millions of vectors efficiently
📊 Architecture Visualisations
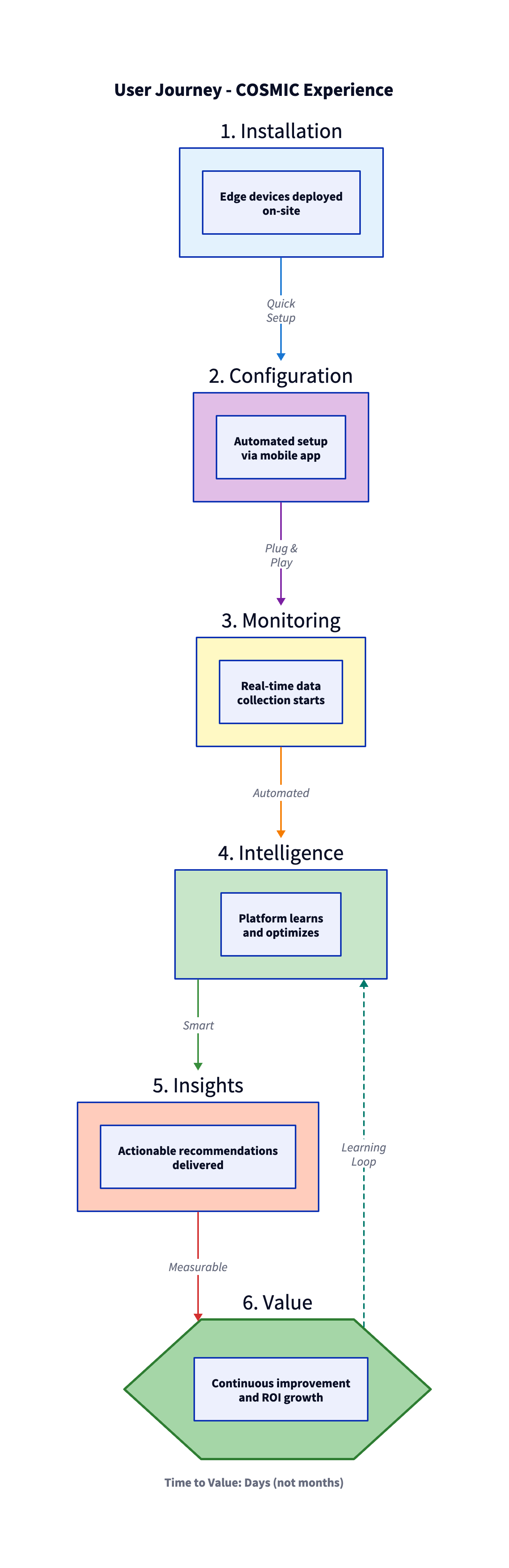
Platform Overview
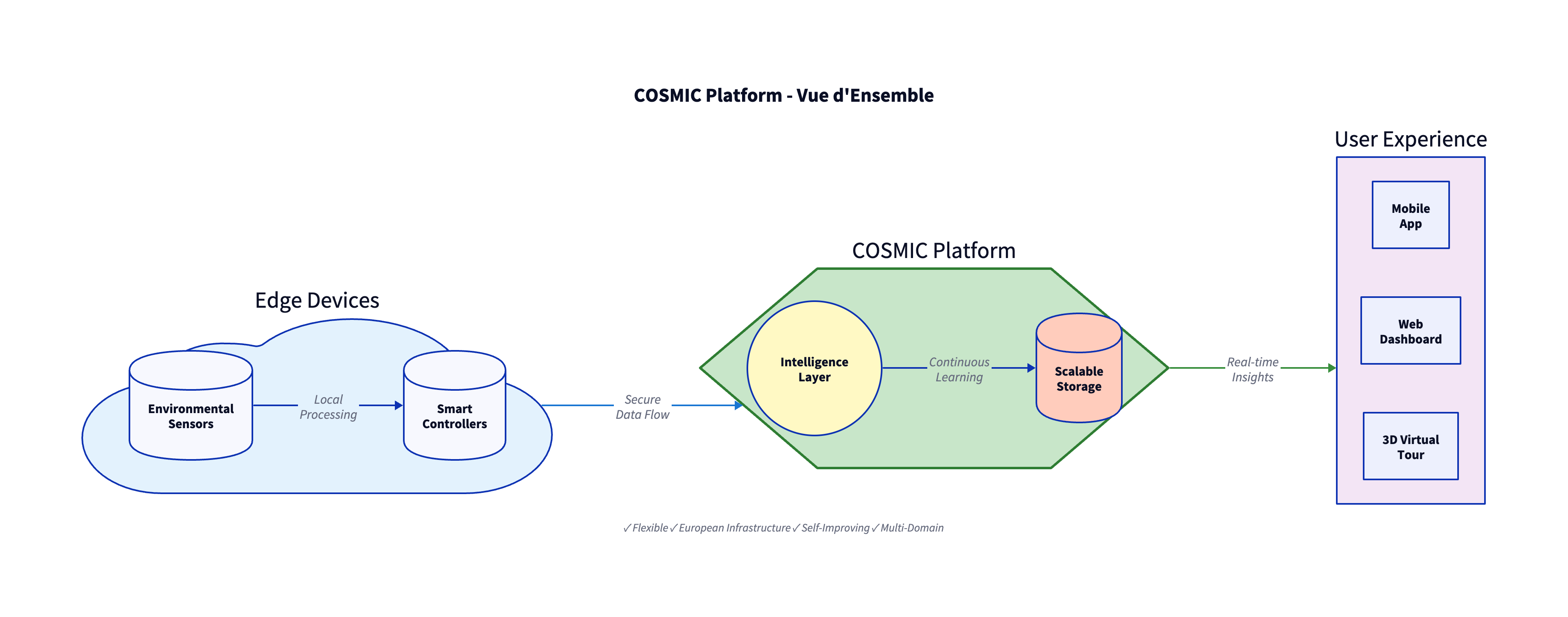
User Journey Flow